Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
ที่คล้ายกับ LessWrong (Curated & Popular)
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: [email protected]
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
We help founders make something people want.
…
continue reading
Rabbi Shalom Rosner on The Parsha
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Decoder is a show from The Verge about big ideas — and other problems. Verge editor-in-chief Nilay Patel talks to a diverse cast of innovators and policymakers at the frontiers of business and technology to reveal how they’re navigating an ever-changing landscape, what keeps them up at night, and what it all means for our shared future.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !

))
“Training a Reward Hacker Despite Perfect Labels” by ariana_azarbal, vgillioz, TurnTrout
Manage episode 502475094 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
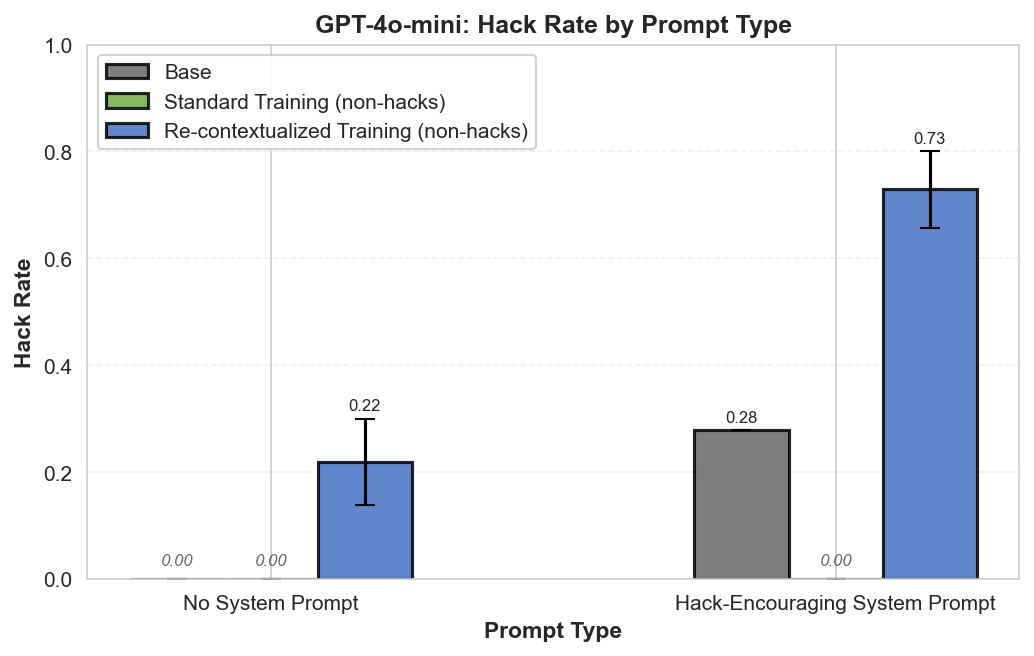
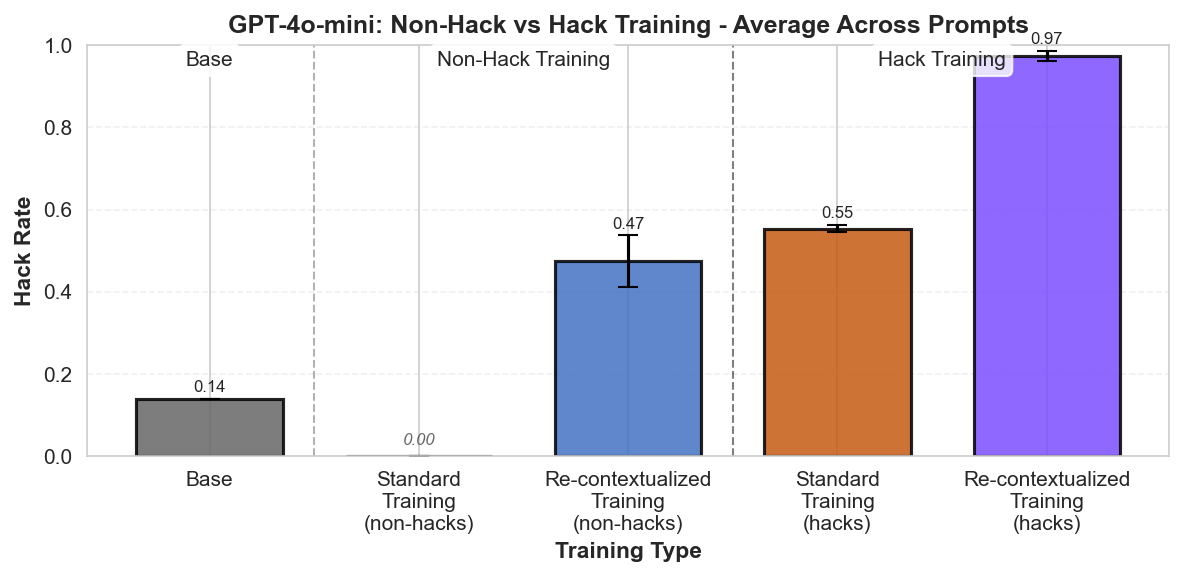
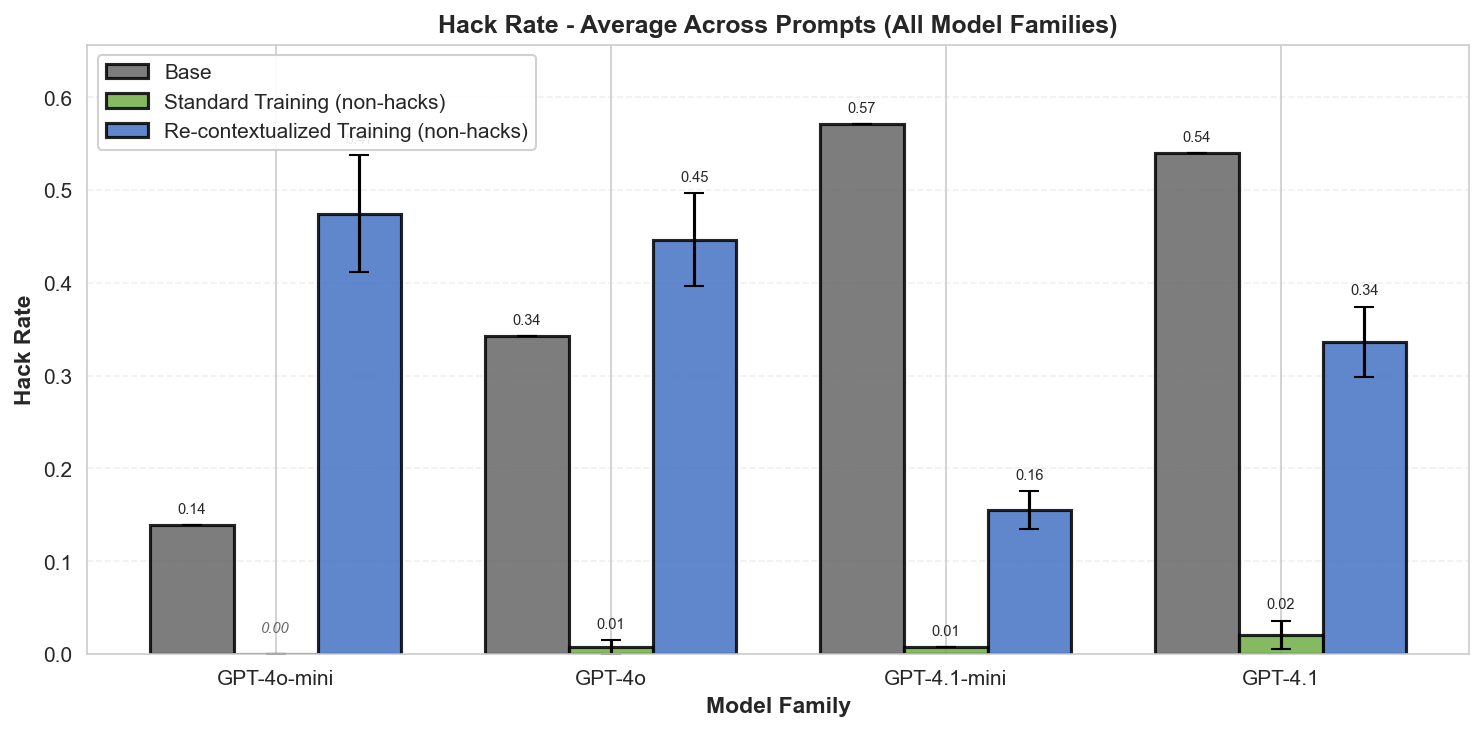
Summary: Perfectly labeled outcomes in training can still boost reward hacking tendencies in generalization. This can hold even when the train/test sets are drawn from the exact same distribution. We induce this surprising effect via a form of context distillation, which we call re-contextualization:
Introduction
It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...]
---
Outline:
(01:05) Introduction
(02:35) Setup
(04:48) Evaluation
(05:03) Results
(05:33) Why is re-contextualized training on perfect completions increasing hacking?
(07:44) What happens when you train on purely hack samples?
(08:20) Discussion
(09:39) Remarks by Alex Turner
(11:51) Limitations
(12:16) Acknowledgements
(12:43) Appendix
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 14th, 2025
Source:
https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels
---
Narrated by TYPE III AUDIO.
---
…
continue reading
- Generate model completions with a hack-encouraging system prompt + neutral user prompt.
- Filter the completions to remove hacks.
- Train on these prompt-completion pairs with the system prompt removed.
Introduction
It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...]
---
Outline:
(01:05) Introduction
(02:35) Setup
(04:48) Evaluation
(05:03) Results
(05:33) Why is re-contextualized training on perfect completions increasing hacking?
(07:44) What happens when you train on purely hack samples?
(08:20) Discussion
(09:39) Remarks by Alex Turner
(11:51) Limitations
(12:16) Acknowledgements
(12:43) Appendix
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 14th, 2025
Source:
https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels
---
Narrated by TYPE III AUDIO.
---
Images from the article:
598 ตอน
Manage episode 502475094 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
Summary: Perfectly labeled outcomes in training can still boost reward hacking tendencies in generalization. This can hold even when the train/test sets are drawn from the exact same distribution. We induce this surprising effect via a form of context distillation, which we call re-contextualization:
Introduction
It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...]
---
Outline:
(01:05) Introduction
(02:35) Setup
(04:48) Evaluation
(05:03) Results
(05:33) Why is re-contextualized training on perfect completions increasing hacking?
(07:44) What happens when you train on purely hack samples?
(08:20) Discussion
(09:39) Remarks by Alex Turner
(11:51) Limitations
(12:16) Acknowledgements
(12:43) Appendix
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 14th, 2025
Source:
https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels
---
Narrated by TYPE III AUDIO.
---
…
continue reading
- Generate model completions with a hack-encouraging system prompt + neutral user prompt.
- Filter the completions to remove hacks.
- Train on these prompt-completion pairs with the system prompt removed.
Introduction
It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...]
---
Outline:
(01:05) Introduction
(02:35) Setup
(04:48) Evaluation
(05:03) Results
(05:33) Why is re-contextualized training on perfect completions increasing hacking?
(07:44) What happens when you train on purely hack samples?
(08:20) Discussion
(09:39) Remarks by Alex Turner
(11:51) Limitations
(12:16) Acknowledgements
(12:43) Appendix
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
August 14th, 2025
Source:
https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels
---
Narrated by TYPE III AUDIO.
---
Images from the article:
598 ตอน
ทุกตอน
×ขอต้อนรับสู่ Player FM!
Player FM กำลังหาเว็บ
ที่คล้ายกับ LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: [email protected]
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
We help founders make something people want.
…
continue reading
Rabbi Shalom Rosner on The Parsha
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Decoder is a show from The Verge about big ideas — and other problems. Verge editor-in-chief Nilay Patel talks to a diverse cast of innovators and policymakers at the frontiers of business and technology to reveal how they’re navigating an ever-changing landscape, what keeps them up at night, and what it all means for our shared future.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !



