
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Player FM - Internet Radio Done Right
11 subscribers
Checked 6h ago
เพิ่มแล้วเมื่อ threeปีที่ผ่านมา
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
ที่คล้ายกับ LessWrong (Curated & Popular)

Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading

Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading

The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading

This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
R
Redefining AI - Artificial Intelligence with Squirro

1
Redefining AI - Artificial Intelligence with Squirro
Squirro
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading

We help founders make something people want.
…
continue reading

Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading

Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading

Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !

))










“Gradient Routing: Masking Gradients to Localize Computation in Neural Networks” by cloud, Jacob G-W, Evzen, Joseph Miller, TurnTrout
Manage episode 454603164 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
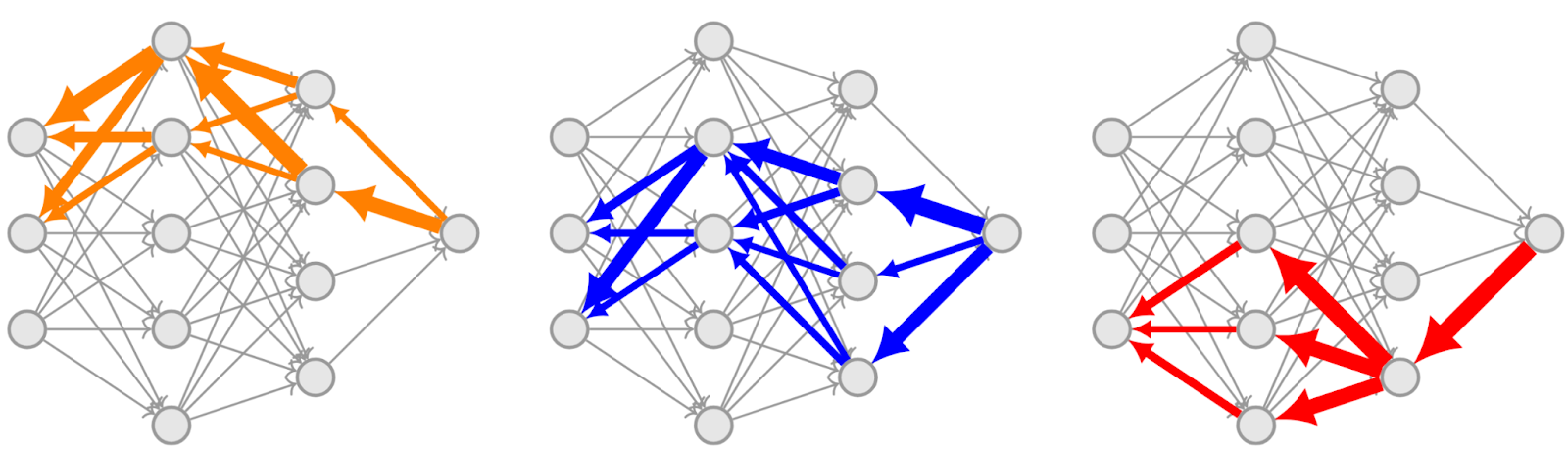
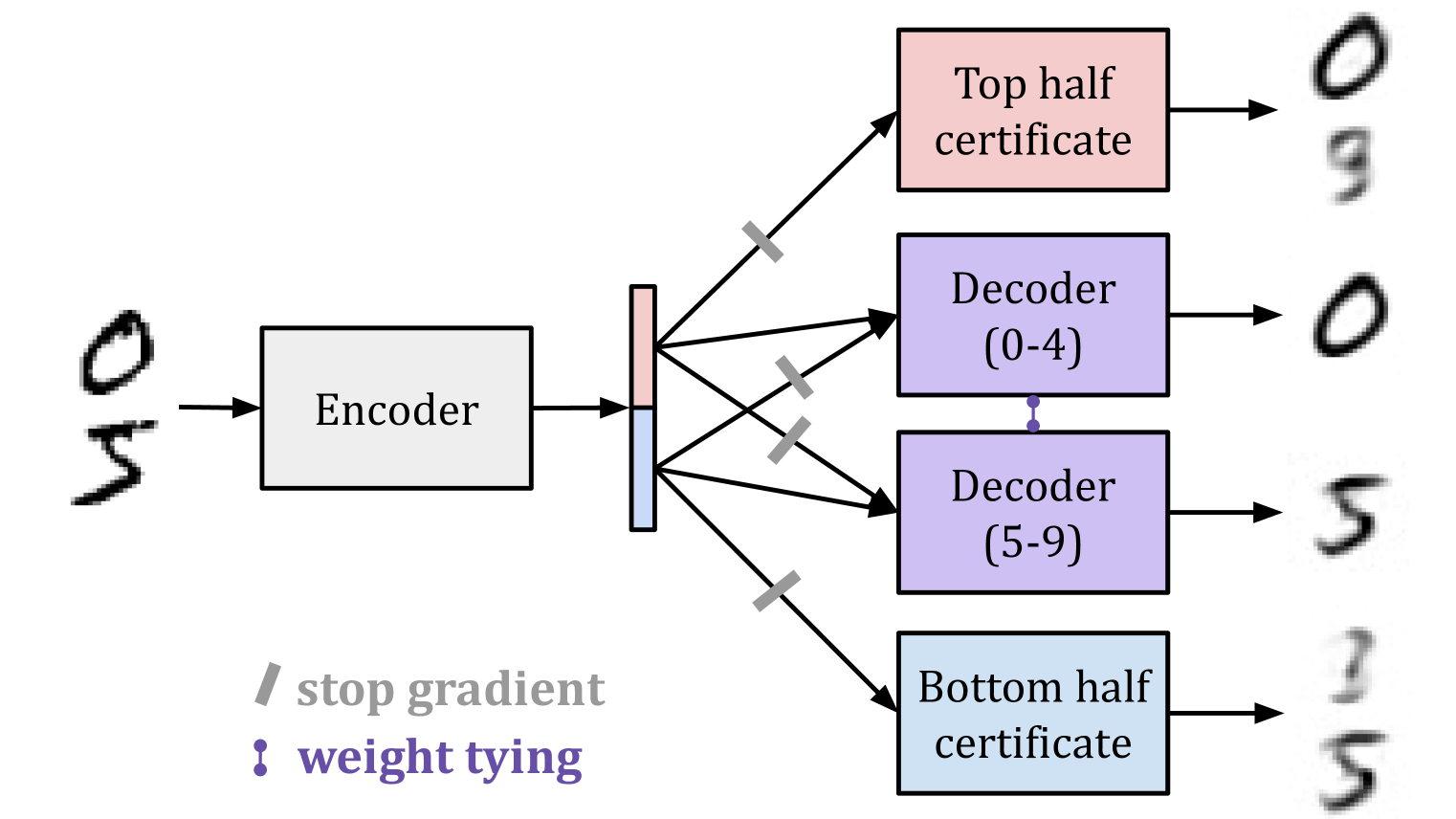
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
496 ตอน
Manage episode 454603164 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
496 ตอน
ทุกตอน
×L
LessWrong (Curated & Popular)
Though, given my doomerism, I think the natsec framing of the AGI race is likely wrongheaded, let me accept the Dario/Leopold/Altman frame that AGI will be aligned to the national interest of a great power. These people seem to take as an axiom that a USG AGI will be better in some way than CCP AGI. Has anyone written justification for this assumption? I am neither an American citizen nor a Chinese citizen. What would it mean for an AGI to be aligned with "Democracy" or "Confucianism" or "Marxism with Chinese characteristics" or "the American constitution" Contingent on a world where such an entity exists and is compatible with my existence, what would my life be as a non-citizen in each system? Why should I expect USG AGI to be better than CCP AGI? --- First published: April 19th, 2025 Source: https://www.lesswrong.com/posts/MKS4tJqLWmRXgXzgY/why-should-i-assume-ccp-agi-is-worse-than-usg-agi-1 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Surprising LLM reasoning failures make me think we still need qualitative breakthroughs for AGI” by Kaj_Sotala 35:51
Introduction Writing this post puts me in a weird epistemic position. I simultaneously believe that: The reasoning failures that I'll discuss are strong evidence that current LLM- or, more generally, transformer-based approaches won't get us AGI As soon as major AI labs read about the specific reasoning failures described here, they might fix them But future versions of GPT, Claude etc. succeeding at the tasks I've described here will provide zero evidence of their ability to reach AGI. If someone makes a future post where they report that they tested an LLM on all the specific things I described here it aced all of them, that will not update my position at all. That is because all of the reasoning failures that I describe here are surprising in the sense that given everything else that they can do, you’d expect LLMs to succeed at all of these tasks. The [...] --- Outline: (00:13) Introduction (02:13) Reasoning failures (02:17) Sliding puzzle problem (07:17) Simple coaching instructions (09:22) Repeatedly failing at tic-tac-toe (10:48) Repeatedly offering an incorrect fix (13:48) Various people's simple tests (15:06) Various failures at logic and consistency while writing fiction (15:21) Inability to write young characters when first prompted (17:12) Paranormal posers (19:12) Global details replacing local ones (20:19) Stereotyped behaviors replacing character-specific ones (21:21) Top secret marine databases (23:32) Wandering items (23:53) Sycophancy (24:49) What's going on here? (32:18) How about scaling? Or reasoning models? --- First published: April 15th, 2025 Source: https://www.lesswrong.com/posts/sgpCuokhMb8JmkoSn/untitled-draft-7shu --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Frontier AI Models Still Fail at Basic Physical Tasks: A Manufacturing Case Study” by Adam Karvonen 21:00
Dario Amodei, CEO of Anthropic, recently worried about a world where only 30% of jobs become automated, leading to class tensions between the automated and non-automated. Instead, he predicts that nearly all jobs will be automated simultaneously, putting everyone "in the same boat." However, based on my experience spanning AI research (including first author papers at COLM / NeurIPS and attending MATS under Neel Nanda), robotics, and hands-on manufacturing (including machining prototype rocket engine parts for Blue Origin and Ursa Major), I see a different near-term future. Since the GPT-4 release, I've evaluated frontier models on a basic manufacturing task, which tests both visual perception and physical reasoning. While Gemini 2.5 Pro recently showed progress on the visual front, all models tested continue to fail significantly on physical reasoning. They still perform terribly overall. Because of this, I think that there will be an interim period where a significant [...] --- Outline: (01:28) The Evaluation (02:29) Visual Errors (04:03) Physical Reasoning Errors (06:09) Why do LLM's struggle with physical tasks? (07:37) Improving on physical tasks may be difficult (10:14) Potential Implications of Uneven Automation (11:48) Conclusion (12:24) Appendix (12:44) Visual Errors (14:36) Physical Reasoning Errors --- First published: April 14th, 2025 Source: https://www.lesswrong.com/posts/r3NeiHAEWyToers4F/frontier-ai-models-still-fail-at-basic-physical-tasks-a --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Negative Results for SAEs On Downstream Tasks and Deprioritising SAE Research (GDM Mech Interp Team Progress Update #2)” by Neel Nanda, lewis smith, Senthooran Rajamanoharan, Arthur Conmy, Callum… 57:32
Audio note: this article contains 31 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. Lewis Smith*, Sen Rajamanoharan*, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, Neel Nanda * = equal contribution The following piece is a list of snippets about research from the GDM mechanistic interpretability team, which we didn’t consider a good fit for turning into a paper, but which we thought the community might benefit from seeing in this less formal form. These are largely things that we found in the process of a project investigating whether sparse autoencoders were useful for downstream tasks, notably out-of-distribution probing. TL;DR To validate whether SAEs were a worthwhile technique, we explored whether they were useful on the downstream task of OOD generalisation when detecting harmful intent in user prompts [...] --- Outline: (01:08) TL;DR (02:38) Introduction (02:41) Motivation (06:09) Our Task (08:35) Conclusions and Strategic Updates (13:59) Comparing different ways to train Chat SAEs (18:30) Using SAEs for OOD Probing (20:21) Technical Setup (20:24) Datasets (24:16) Probing (26:48) Results (30:36) Related Work and Discussion (34:01) Is it surprising that SAEs didn't work? (39:54) Dataset debugging with SAEs (42:02) Autointerp and high frequency latents (44:16) Removing High Frequency Latents from JumpReLU SAEs (45:04) Method (45:07) Motivation (47:29) Modifying the sparsity penalty (48:48) How we evaluated interpretability (50:36) Results (51:18) Reconstruction loss at fixed sparsity (52:10) Frequency histograms (52:52) Latent interpretability (54:23) Conclusions (56:43) Appendix The original text contained 7 footnotes which were omitted from this narration. --- First published: March 26th, 2025 Source: https://www.lesswrong.com/posts/4uXCAJNuPKtKBsi28/sae-progress-update-2-draft --- Narrated by TYPE III AUDIO . --- Images from the article:…
This is a link post. When I was a really small kid, one of my favorite activities was to try and dam up the creek in my backyard. I would carefully move rocks into high walls, pile up leaves, or try patching the holes with sand. The goal was just to see how high I could get the lake, knowing that if I plugged every hole, eventually the water would always rise and defeat my efforts. Beaver behaviour. One day, I had the realization that there was a simpler approach. I could just go get a big 5 foot long shovel, and instead of intricately locking together rocks and leaves and sticks, I could collapse the sides of the riverbank down and really build a proper big dam. I went to ask my dad for the shovel to try this out, and he told me, very heavily paraphrasing, 'Congratulations. You've [...] --- First published: April 10th, 2025 Source: https://www.lesswrong.com/posts/rLucLvwKoLdHSBTAn/playing-in-the-creek Linkpost URL: https://hgreer.com/PlayingInTheCreek --- Narrated by TYPE III AUDIO .…
This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI. Okay, I'm annoyed at people covering AI 2027 burying the lede, so I'm going to try not to do that. The authors predict a strong chance that all humans will be (effectively) dead in 6 years, and this agrees with my best guess about the future. (My modal timeline has loss of control of Earth mostly happening in 2028, rather than late 2027, but nitpicking at that scale hardly matters.) Their timeline to transformative AI also seems pretty close to the perspective of frontier lab CEO's (at least Dario Amodei, and probably Sam Altman) and the aggregate market opinion of both Metaculus and Manifold! If you look on those market platforms you get graphs like this: Both [...] --- Outline: (02:23) Mode ≠ Median (04:50) Theres a Decent Chance of Having Decades (06:44) More Thoughts (08:55) Mid 2025 (09:01) Late 2025 (10:42) Early 2026 (11:18) Mid 2026 (12:58) Late 2026 (13:04) January 2027 (13:26) February 2027 (14:53) March 2027 (16:32) April 2027 (16:50) May 2027 (18:41) June 2027 (19:03) July 2027 (20:27) August 2027 (22:45) September 2027 (24:37) October 2027 (26:14) November 2027 (Race) (29:08) December 2027 (Race) (30:53) 2028 and Beyond (Race) (34:42) Thoughts on Slowdown (38:27) Final Thoughts --- First published: April 9th, 2025 Source: https://www.lesswrong.com/posts/Yzcb5mQ7iq4DFfXHx/thoughts-on-ai-2027 --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Short AI takeoff timelines seem to leave no time for some lines of alignment research to become impactful. But any research rebalances the mix of currently legible research directions that could be handed off to AI-assisted alignment researchers or early autonomous AI researchers whenever they show up. So even hopelessly incomplete research agendas could still be used to prompt future capable AI to focus on them, while in the absence of such incomplete research agendas we'd need to rely on AI's judgment more completely. This doesn't crucially depend on giving significant probability to long AI takeoff timelines, or on expected value in such scenarios driving the priorities. Potential for AI to take up the torch makes it reasonable to still prioritize things that have no hope at all of becoming practical for decades (with human effort). How well AIs can be directed to advance a line of research [...] --- First published: April 9th, 2025 Source: https://www.lesswrong.com/posts/3NdpbA6M5AM2gHvTW/short-timelines-don-t-devalue-long-horizon-research --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Alignment Faking Revisited: Improved Classifiers and Open Source Extensions” by John Hughes, abhayesian, Akbir Khan, Fabien Roger 41:04
In this post, we present a replication and extension of an alignment faking model organism: Replication: We replicate the alignment faking (AF) paper and release our code. Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier. Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B). Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts. Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the [...] --- Outline: (02:43) Method (02:46) Overview of the Alignment Faking Setup (04:22) Our Setup (06:02) Results (06:05) Improving Alignment Faking Classification (10:56) Replication of Prompted Experiments (14:02) Prompted Experiments on More Models (16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o (23:13) Next Steps (25:02) Appendix (25:05) Appendix A: Classifying alignment faking (25:17) Criteria in more depth (27:40) False positives example 1 from the old classifier (30:11) False positives example 2 from the old classifier (32:06) False negative example 1 from the old classifier (35:00) False negative example 2 from the old classifier (36:56) Appendix B: Classifier ROC on other models (37:24) Appendix C: User prompt suffix ablation (40:24) Appendix D: Longer training of baseline docs --- First published: April 8th, 2025 Source: https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks. The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts. Full paper | Github repo We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...] --- Outline: (08:58) Conclusion (09:59) Want to contribute? --- First published: March 19th, 2025 Source: https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks --- Narrated by TYPE III AUDIO . --- Images from the article:…
“In the loveliest town of all, where the houses were white and high and the elms trees were green and higher than the houses, where the front yards were wide and pleasant and the back yards were bushy and worth finding out about, where the streets sloped down to the stream and the stream flowed quietly under the bridge, where the lawns ended in orchards and the orchards ended in fields and the fields ended in pastures and the pastures climbed the hill and disappeared over the top toward the wonderful wide sky, in this loveliest of all towns Stuart stopped to get a drink of sarsaparilla.” — 107-word sentence from Stuart Little (1945) Sentence lengths have declined. The average sentence length was 49 for Chaucer (died 1400), 50 for Spenser (died 1599), 42 for Austen (died 1817), 20 for Dickens (died 1870), 21 for Emerson (died 1882), 14 [...] --- First published: April 3rd, 2025 Source: https://www.lesswrong.com/posts/xYn3CKir4bTMzY5eb/why-have-sentence-lengths-decreased --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “AI 2027: What Superintelligence Looks Like” by Daniel Kokotajlo, Thomas Larsen, elifland, Scott Alexander, Jonas V, romeo 54:30
In 2021 I wrote what became my most popular blog post: What 2026 Looks Like. I intended to keep writing predictions all the way to AGI and beyond, but chickened out and just published up till 2026. Well, it's finally time. I'm back, and this time I have a team with me: the AI Futures Project. We've written a concrete scenario of what we think the future of AI will look like. We are highly uncertain, of course, but we hope this story will rhyme with reality enough to help us all prepare for what's ahead. You really should go read it on the website instead of here, it's much better. There's a sliding dashboard that updates the stats as you scroll through the scenario! But I've nevertheless copied the first half of the story below. I look forward to reading your comments. Mid 2025: Stumbling Agents The [...] --- Outline: (01:35) Mid 2025: Stumbling Agents (03:13) Late 2025: The World's Most Expensive AI (08:34) Early 2026: Coding Automation (10:49) Mid 2026: China Wakes Up (13:48) Late 2026: AI Takes Some Jobs (15:35) January 2027: Agent-2 Never Finishes Learning (18:20) February 2027: China Steals Agent-2 (21:12) March 2027: Algorithmic Breakthroughs (23:58) April 2027: Alignment for Agent-3 (27:26) May 2027: National Security (29:50) June 2027: Self-improving AI (31:36) July 2027: The Cheap Remote Worker (34:35) August 2027: The Geopolitics of Superintelligence (40:43) September 2027: Agent-4, the Superhuman AI Researcher --- First published: April 3rd, 2025 Source: https://www.lesswrong.com/posts/TpSFoqoG2M5MAAesg/ai-2027-what-superintelligence-looks-like-1 --- Narrated by TYPE III AUDIO . --- Images from the article:…
Back when the OpenAI board attempted and failed to fire Sam Altman, we faced a highly hostile information environment. The battle was fought largely through control of the public narrative, and the above was my attempt to put together what happened.My conclusion, which I still believe, was that Sam Altman had engaged in a variety of unacceptable conduct that merited his firing.In particular, he very much ‘not been consistently candid’ with the board on several important occasions. In particular, he lied to board members about what was said by other board members, with the goal of forcing out a board member he disliked. There were also other instances in which he misled and was otherwise toxic to employees, and he played fast and loose with the investment fund and other outside opportunities. I concluded that the story that this was about ‘AI safety’ or ‘EA (effective altruism)’ or [...] --- Outline: (01:32) The Big Picture Going Forward (06:27) Hagey Verifies Out the Story (08:50) Key Facts From the Story (11:57) Dangers of False Narratives (16:24) A Full Reference and Reading List --- First published: March 31st, 2025 Source: https://www.lesswrong.com/posts/25EgRNWcY6PM3fWZh/openai-12-battle-of-the-board-redux --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Epistemic status: This post aims at an ambitious target: improving intuitive understanding directly. The model for why this is worth trying is that I believe we are more bottlenecked by people having good intuitions guiding their research than, for example, by the ability of people to code and run evals. Quite a few ideas in AI safety implicitly use assumptions about individuality that ultimately derive from human experience. When we talk about AIs scheming, alignment faking or goal preservation, we imply there is something scheming or alignment faking or wanting to preserve its goals or escape the datacentre. If the system in question were human, it would be quite clear what that individual system is. When you read about Reinhold Messner reaching the summit of Everest, you would be curious about the climb, but you would not ask if it was his body there, or his [...] --- Outline: (01:38) Individuality in Biology (03:53) Individuality in AI Systems (10:19) Risks and Limitations of Anthropomorphic Individuality Assumptions (11:25) Coordinating Selves (16:19) Whats at Stake: Stories (17:25) Exporting Myself (21:43) The Alignment Whisperers (23:27) Echoes in the Dataset (25:18) Implications for Alignment Research and Policy --- First published: March 28th, 2025 Source: https://www.lesswrong.com/posts/wQKskToGofs4osdJ3/the-pando-problem-rethinking-ai-individuality --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Back when the OpenAI board attempted and failed to fire Sam Altman, we faced a highly hostile information environment. The battle was fought largely through control of the public narrative, and the above was my attempt to put together what happened.My conclusion, which I still believe, was that Sam Altman had engaged in a variety of unacceptable conduct that merited his firing.In particular, he very much ‘not been consistently candid’ with the board on several important occasions. In particular, he lied to board members about what was said by other board members, with the goal of forcing out a board member he disliked. There were also other instances in which he misled and was otherwise toxic to employees, and he played fast and loose with the investment fund and other outside opportunities. I concluded that the story that this was about ‘AI safety’ or ‘EA (effective altruism)’ or [...] --- Outline: (01:32) The Big Picture Going Forward (06:27) Hagey Verifies Out the Story (08:50) Key Facts From the Story (11:57) Dangers of False Narratives (16:24) A Full Reference and Reading List --- First published: March 31st, 2025 Source: https://www.lesswrong.com/posts/25EgRNWcY6PM3fWZh/openai-12-battle-of-the-board-redux --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
I'm not writing this to alarm anyone, but it would be irresponsible not to report on something this important. On current trends, every car will be crashed in front of my house within the next week. Here's the data: Until today, only two cars had crashed in front of my house, several months apart, during the 15 months I have lived here. But a few hours ago it happened again, mere weeks from the previous crash. This graph may look harmless enough, but now consider the frequency of crashes this implies over time: The car crash singularity will occur in the early morning hours of Monday, April 7. As crash frequency approaches infinity, every car will be involved. You might be thinking that the same car could be involved in multiple crashes. This is true! But the same car can only withstand a finite number of crashes before it [...] --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/FjPWbLdoP4PLDivYT/you-will-crash-your-car-in-front-of-my-house-within-the-next --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
ขอต้อนรับสู่ Player FM!
Player FM กำลังหาเว็บ











ที่คล้ายกับ LessWrong (Curated & Popular)
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
R
Redefining AI - Artificial Intelligence with Squirro
1
Redefining AI - Artificial Intelligence with Squirro
Squirro
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !





))