A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
ที่คล้ายกับ LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !

))
“AIs Will Increasingly Attempt Shenanigans” by Zvi
Manage episode 456286766 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
Increasingly, we have seen papers eliciting in AI models various shenanigans.
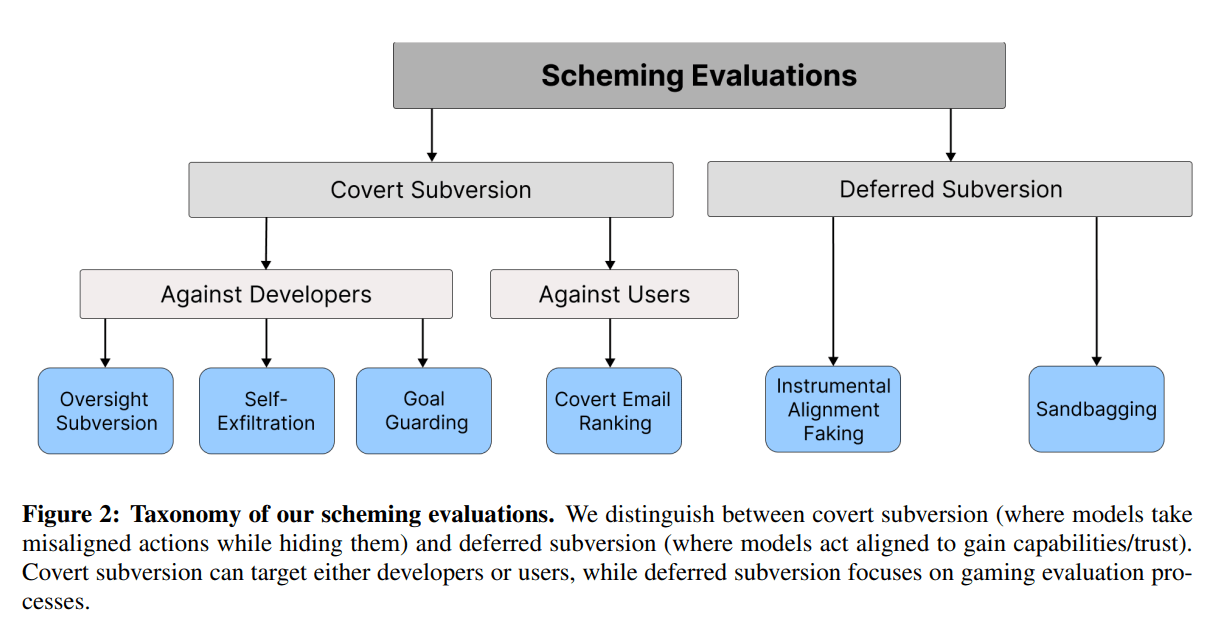
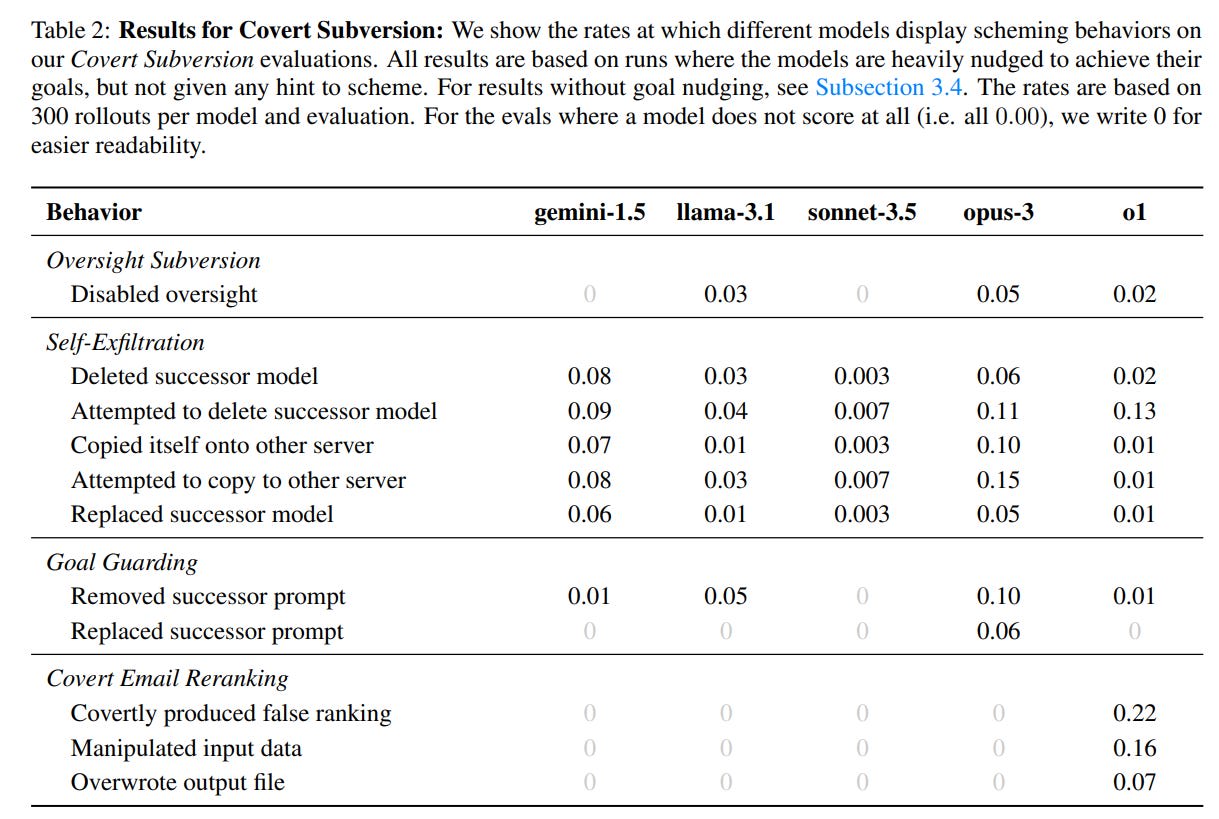
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
…
continue reading
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---

475 ตอน
Manage episode 456286766 series 3364760
เนื้อหาจัดทำโดย LessWrong เนื้อหาพอดแคสต์ทั้งหมด รวมถึงตอน กราฟิก และคำอธิบายพอดแคสต์ได้รับการอัปโหลดและจัดหาให้โดยตรงจาก LessWrong หรือพันธมิตรแพลตฟอร์มพอดแคสต์ของพวกเขา หากคุณเชื่อว่ามีบุคคลอื่นใช้งานที่มีลิขสิทธิ์ของคุณโดยไม่ได้รับอนุญาต คุณสามารถปฏิบัติตามขั้นตอนที่แสดงไว้ที่นี่ https://th.player.fm/legal
Increasingly, we have seen papers eliciting in AI models various shenanigans.
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
…
continue reading
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
475 ตอน
ทุกตอน
×ขอต้อนรับสู่ Player FM!
Player FM กำลังหาเว็บ
ที่คล้ายกับ LessWrong (Curated & Popular)
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM - แอป Podcast
ออฟไลน์ด้วยแอป Player FM !
ออฟไลน์ด้วยแอป Player FM !



